Optimizing Triangles for a Full-screen Pass
Two tri or not two tri?
Something that comes up often in real-time rendering engines is the need to run a full-screen pixel shader. It’s pretty common for screen space effects, to name the big ones: screen-space reflections and screen-space ambient occlusion. However, in order to render a full-screen pixel shader pass, you need to fill the screen with geometry. And so the big question I want to talk about is…
Should you render with 2 triangles that fit the viewport perfectly?
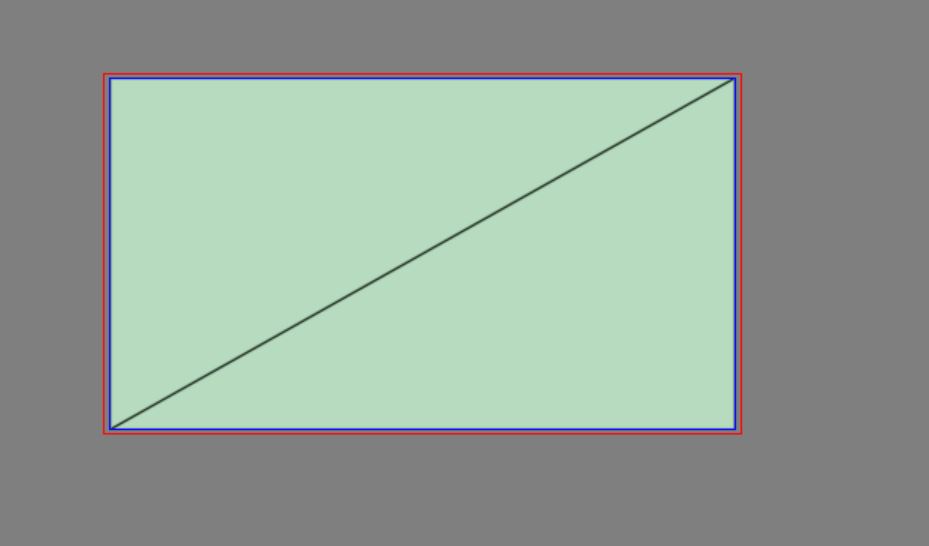
Or 1 massive triangle that spills over the sides of the viewport?
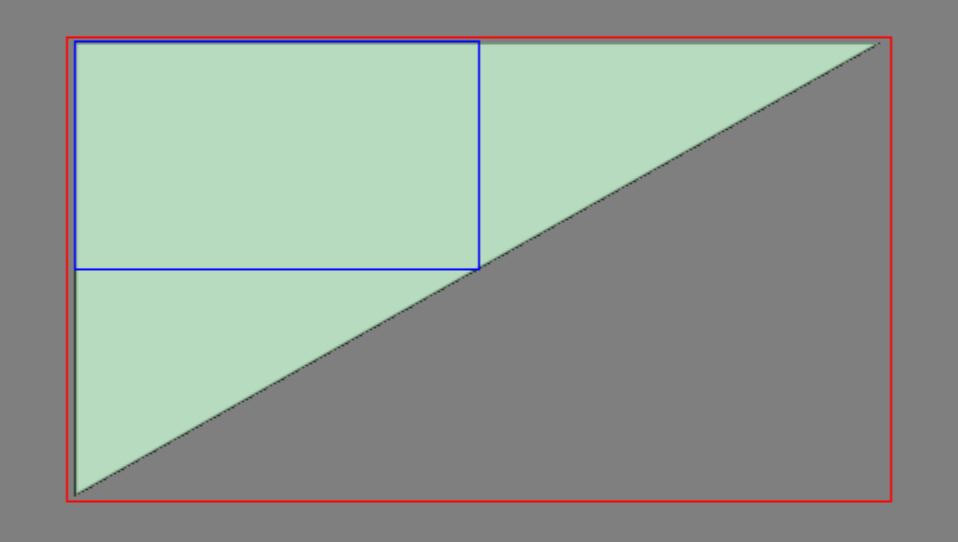 The blue rectangle represents the viewport. Red is the bounds of the geometry
The blue rectangle represents the viewport. Red is the bounds of the geometry
Performance
So before jumping into any theories, lets just do some profiling with Pix!
I’ll be testing with the D3D12 Hello World sample from the DirectX Samples. By default it just splats a triangle on the screen so I just made some tweaks so that triangle fills the screen and a toggle so I can go back and forth between the 1 triangle version and the 2 triangle version. I’m testing on an RTX 2070 at 512x512 (I’ll explain the odd choice of resolution later), but it’s worth pointing out that the results we find occur on AMD as well.
With a pixel shader that just outputs a solid color, it’s insanely fast. In both cases it’s around 8 microseconds. We can infer a couple of things from this: there’s no visible overhead to the clipping happening in the 1-triangle case and no real overhead to the 3 extra triangles in the 2-triangle.
So I changed the pixel shader to this silly thing just to “emulate” a heavy-weight pixel shader:
float4 PSMain(PSInput input) : SV_TARGET
{
float r = input.position.x;
for (uint i = 0; i < 10000; i++)
{
r = sin(r);
}
return float4(r, 0, 0, 1);
}And this is where things get interesting, here’s the performance (in milliseconds):
1 triangle: 3.33 ms
2 triangle: 3.43 ms
So 2 triangle case is about 0.1 ms slower. It’s small enough difference that it could be noise but after re-running it several times, the results are actually pretty consistent. This might seem a little surprising since we’ve only tweaked the pixel shader and both cases should result in the same amount of pixels being drawn. So what’s going on??
Quads
In order to answer that, we need to talk about GPU quads. Specifically, there’s a quirk to fixed function rasterization where things always render as batches of 2x2 pixel quads. Regardless of whether your triangle is only the size of a single pixel, the GPU will actually a full 2x2 quad even if 3 of those pixels don’t really exist (the other 3 pixels are called “helper pixels”). The primary reason for this is so that the GPU can calculate derivatives to help “auto-magically” pick the correct teture mip. To go fully deep on why quads are a thing warrants it’s own post, but there’s some good resources for that, A Trip through the graphics pipeline being one of the best.
This silly seeming quad behavior has all kinds of implications for GPU performance. But it’s one of the big reasons GPU’s handle sub-pixel triangles so poorly (and why things like compute-shader-based rasterization can be so interesting).
So what’s all this have to do with rendering 2 full-screen triangles? The problem comes down the diagonal edge that gets formed between the triangles.
Lets make this even simpler and look at how these 2 triangles rasterize out on a 6x6 render target (warning: mspaint art incoming):
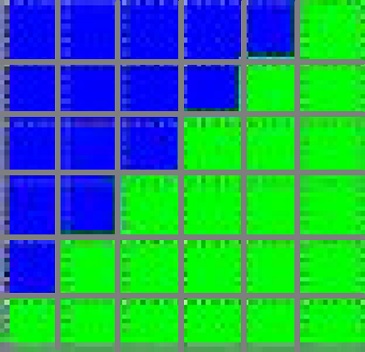
The top triangle is rendering blue and the bottom triangle is rendering green. It’s worth pointing out on the diagonal line of pixels are exactly between the triangles and so it should be 50:50 green and blue, but the rasterizer has to pick one (unless you’re using MSAA). In order to break this tie-breaker there’s actually a rule for this situation called the “Top-Left” rule that’s causing the green triangle to “win”. Essentially the triangle whose top-left edge covers the pixel centroid gets priority.
So lets first talk about how the blue triangle gets turned into quads. I’ve added a magenta overlay on how I’m guessing this might get packed up into 2x2 pixel quads:
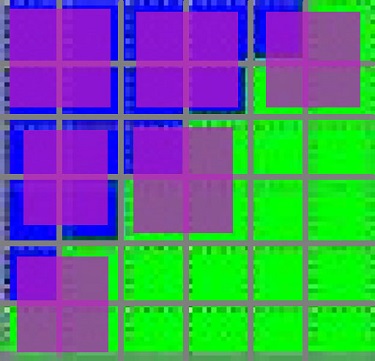
First, to be clear this is just a guess at how the GPU might turn this into quads, they could be subtley different or “smarter” perhaps but I actually doubt it (and some math/counter information later on that will back this up). But the main point here is you’ll see there’s quads that are forced to bleed onto the green triangle. What’s important to know is that the overlapped quads will still run 4 pixel shader invocations even if only 1 pixel of the quad is within the triangle. And 3 “wasted” helper pixels can’t try to be smart and write out the green triangles information because it only has access to the blue triangle’s interpolated vertex information.
Now let’s see about how the green triangle gets turned into quads:

And so NOW we can finally talk about the crux of the problem, all of these quads are essentially getting run twice:
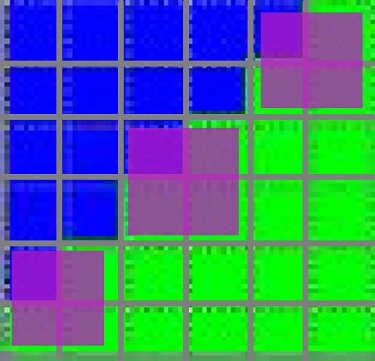
So let me sum that all up: the diagonal edge between the triangles cause overlapping quads that result in the pixel shader getting called twice for all pixels along this edge.
At this point you probably have a lot of questions. I’ll try to anticipate a couple of them and answer them to the best of my ability but to be honest this starts to get into murky hardware territory that isn’t my expertise. But the big one is probably “Why does it feel like it’s processing the triangles one-at-a-time? Can’t it just rasterize them all together?” It certainly is doing them all in parallell, but it’s important to keep in mind that pipelining is a big part of what makes a GPU fast. GPUs these days are insanely wide and it’s quite challenging to keeping the whole thing busy. The best way is just making sure you start rasterizing and running pixel shader invocations as soon as possible. And that means turning your vertex shader work into pixels ASAP, even if it means inefficiecies like this quad overlap mess.
Another question is “Are helper pixels even needed in this case?”. With this simple pixel shader, the helper pixel are absolutely useless, there’s no need for derivatives since I’m not using a texture read. But the fixed-function is just, well “fixed” to work in this way and there’s no any way to get around this (other writing a compute shader rasterizer).
Nice theory…can you prove it?
Yes we can! Lets bring out our ol’ friend Pix again…
So what we want to do is find out how many quads actually got run for a draw. Unfortunately Pix doesn’t have a vendor-agnostic way of querying this (edit: Dr Pix can display this in both a vendor-agnostic AND more informative way, details at the bottom of this post). However, it DOES have some handshakes with the driver that allows it to get hardware-specific counters with more low-level insights. I’m using an NVidia GPU so I’ll be working with their specific counter, but other vendors will have something similar. The counter I’m interested in is “sm__ps_quads_launched.sum”:
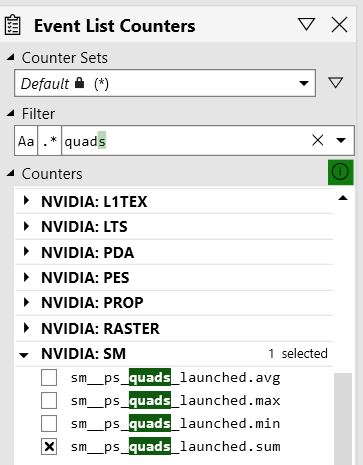
The counter names can sometimes be pretty overwhelming due to acronyms, this one isn’t too bad but I’ll break it down for clarity. You can ignore the sm (“Streaming Multiprocessor”), it’s basically just the category this counter falls into. The ps is of course Pixel Shader, we just talked about what quads launched, and then the sum is saying that this counter is going to sum up all the quads launched for the selected draw. Hey, that’s exactly what we want, nice!
So lets look at the counter for the 1 triangle case:

65,536 quads huh? With some quick math, we can verify that makes sense. The render target is 512x512 and a 2x2 pixel quad contains 4 pixels so:
512 pixels * 512 pixels / (4 pixels per quad) = 65536 quadsMath checks out! Let’s move on to the 2 triangle case:
 65792 quads, more quads that the single triangle case, which lines up with my quad theory! In fact, that’s exactly 256 more quads than the 1 tri case. In fact, this is exactly what you’d expect if you think about it. The width of the render target is 512 pixels, and you’d expect an extra quad every 2 pixels due to the diagonal edge, so 512px / 2px = 256 extra quads! Note that that math would need to be tweaked based on aspect ratio if the height and width weren’t the same, but I rigged the dimensions for some easy math.
65792 quads, more quads that the single triangle case, which lines up with my quad theory! In fact, that’s exactly 256 more quads than the 1 tri case. In fact, this is exactly what you’d expect if you think about it. The width of the render target is 512 pixels, and you’d expect an extra quad every 2 pixels due to the diagonal edge, so 512px / 2px = 256 extra quads! Note that that math would need to be tweaked based on aspect ratio if the height and width weren’t the same, but I rigged the dimensions for some easy math.
Conclusion
So hopefully that’s convinced you to use 1 triangle over 2 triangles! It’s worth noting I’ve set things up in a way that exaggerates the problem slightly. As your resolution goes up, the less this matters because the ratio of quads due to the diagonal to quads from the rest of the triangle will get smaller and smaller. In an optimized game running at 4k on a modern GPU, is this a meaningful difference? My guess is you’re not going to get more than 0.1 millisecond savings out of it (unless maybe you’re using inline raytracing in a fullscreen pass). But let me tell you, if you’re a rendering engineer optimizing for 60 FPS, an easy 0.1ms savings is like hitting the lottery!
And if none of that is enough to convince you, the single triangle case is also just easier to setup. You don’t even need a vertex buffer, you can procedurally generate the points in the vertex shader using SV_VertexID:
float4 main( uint id : SV_VertexID ) : SV_POSITION
{
float2 uv = float2((id << 1) & 2, id & 2);
return float4(uv * float2(2, -2) + float2(-1, 1), 0, 1);
}Update
Austin Kinross kindly pointed out there’s actually another VERY cool way to query quad profiling information using Dr Pix:
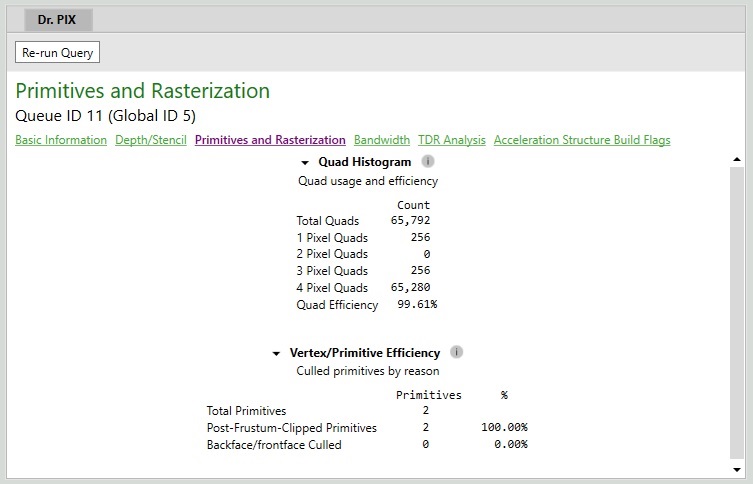
Acknowledgement
This isn’t my discovery or anything, this is largely inspired from a StackOverflow answer from Derhass. His answer is pretty comprehensive but I thought it was so fascinating that it was worth digging up performance and counter information to really break it down more concretely.